RECENT POSTS
- Introducing modelx-cython: Boosting modelx with Cython Compilation
- A First Look at Python in Excel
- Enhanced Speed for Exported lifelib Models
- New Feature: Export Models as Self-contained Python Packages
- Why you should use modelx
- New MxDataView in spyder-modelx v0.13.0
- Building an object-oriented model with modelx
- Why dynamic ALM models are slow
- Running a heavy model while saving memory
- Running modelx in parallel using ipyparallel
- All posts ...
modelx 0.9.0 introduces a new interface to Excel
Aug 10, 2020 • Fumito Hamamura
In my last post, I wrote about 2 ideas to simplify lifelib models. One of the idea was to simplify input loading from Excel. I released modelx 0.9.0 yesterday, and this version introduces a new way to read and write values in Excel files.
New interface to Excel files
Model and UserSpace objects now have a new method, new_excel_range. This method creates an ExcelRange object, which acts like a dict, and assigns it to a Reference. Through the ExcelRange object, you can get values from a range in an Excel file and set values in the range. When the Model containing the Referece is written to a Model foler, the entire input Excel file is saved with the Model, reflecting changes made through the ExcelRange object. When the Model is read back, the ExcelRange object is initialized from the data in the saved Excel file. A Model can have multiple ExcelRange objects from multiple Excel files, as long as underlying Excel ranges do not overlap.
This version only introduces the interface to Excel files, but under the hood, an abstract IO mechanism is also introduced, which enables loading multiple pieces of data from a single file into multiple data objects, and saving back the data into a single file. This design makes it possible to support new types of data sources, just by writing implementations specific to the new types, and eventually let users define their own IO to support new data sources to meet their own needs.
Example
In the attached sample Excel file, ExcelRangeSample.xlsx, the following table is input in the range C4:G10 on Sheet1.
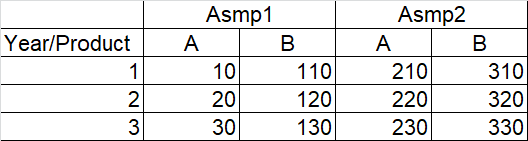
The next new_excel_range method call creates a Reference named Table as given as the first argument, and also creates an ExcelRange object and assigns the object to the Reference. The ExcelRange object reads data from the range C4:G10 on Sheet1 in ExcelRangeSample.xlsx, as specified by the third, fourth and last parameters. The list passed to the keyids parameter, ["r0", "r1", "c0"] denotes that values in the first row ("r0"), the second row ("r1"), and the first column ("c0") should be interpreted as keys in that order, and values in other rows or columns should be interpreted as values associated to the keys.
>>> import modelx as mx
>>> m, s = mx.new_model("Model"), mx.new_space("Test")
>>> s.new_excel_range("Table", "files/Table.xlsx", "C4:G10",
... sheet="Sheet1", keyids=["r0", "r1", "c0"],
... loadpath="ExcelRangeSample.xlsx")
<modelx.io.excelio.ExcelRange at 0x202fefc0548>
The ExcelRange object, as referenced by the Referece Table, is a mapping object, so it acts like a dict. You can get a value for a certain key by passing the key in [] operator, and also set the value for the key using the same subscription ([]) operator. It also supports all the mapping methods, such as keys, values and items.
>>> s.Table
<modelx.io.excelio.ExcelRange at 0x202fefc0548>
>>> dict(s.Table)
{('Asmp1', 'A', 1): 10,
('Asmp1', 'A', 2): 20,
('Asmp1', 'A', 3): 30,
('Asmp1', 'B', 1): 110,
('Asmp1', 'B', 2): 120,
('Asmp1', 'B', 3): 130,
('Asmp2', 'A', 1): 210,
('Asmp2', 'A', 2): 220,
('Asmp2', 'A', 3): 230,
('Asmp2', 'B', 1): 310,
('Asmp2', 'B', 2): 320,
('Asmp2', 'B', 3): 330}
>>> s.Table['Asmp1', 'B', 3]
130
>>> s.Table['Asmp1', 'B', 3] = 260
>>> s.Table['Asmp1', 'B', 3]
260
>>> {k[2]: v for k, v in s.Table.items() if k[0] == 'Asmp1' and k[1] == 'A'}
{1: 10, 2: 20, 3: 30}
When writing the Model to a folder, the ExcelRange object is output to an Excel file and the file is saved with the name in the location specified by the second argument to the new_excel_range method ("files/Table.xlsx"). The file path is interpreted as relative to the Model path, so the output file Table.xlsx is saved under the files folder in the Model folder, Model.
When the Model is read back, the ExcelRange object is populated with the data read from Table.xlsx. You can check that the value for the key ('Asmp1', 'B', 3) has changed in Table.xlsx, and also in the Model, NewModel, which is read back from the Sample folder.
>>> m.write("Model")
>>> mx.read_model("Sample", name="NewModel")
<Model NewModel>
>>> dict(s.Table)
{('Asmp1', 'A', 1): 10,
('Asmp1', 'A', 2): 20,
('Asmp1', 'A', 3): 30,
('Asmp1', 'B', 1): 110,
('Asmp1', 'B', 2): 120,
('Asmp1', 'B', 3): 260,
('Asmp2', 'A', 1): 210,
('Asmp2', 'A', 2): 220,
('Asmp2', 'A', 3): 230,
('Asmp2', 'B', 1): 310,
('Asmp2', 'B', 2): 320,
('Asmp2', 'B', 3): 330}
The old methods to interface with Excel files
modelx had new_space_from_excel, new_cells_form_excel, methods to interface with Excel files before the introduction of the new interface, and these methods are still available. However, the implementation of these methods will be modified in future.
These methods create Cells and UserSpace objects, based on the arguments passed to the methods and on the information stored in the input Excel files as table headers. Currently the Cells and UserSpaces created by the methods are treated differently from those created by normal construction methods, such as new_space, new_cells and defcells, and carry the information on the methods’ arguments inside the objects themselves so that the objects can be reconstructed form the methods and the input Excel file when the Model is deserialized. This implementation will be changed at some future release, and the objects created by these methods will be treated the same way as the objects created by the normal construction methods, and no information about their construction methods and arguments will be retained. Consequently, no input files for these method will be saved with the Models.